Maximizing BOYD performance with CUR datasets
AWS Cost and Usage Report (CUR) datasets typically contain in excess of 100+ columns, depending on services in use and cost allocation tags included in the data. Trying to make sense of what is available and, more importantly, valuable to your use case can require substantial effort.
Most of the CUR line_item_ columns are almost always populated and useful, while a few are essential for the minimal operation of BOYD.
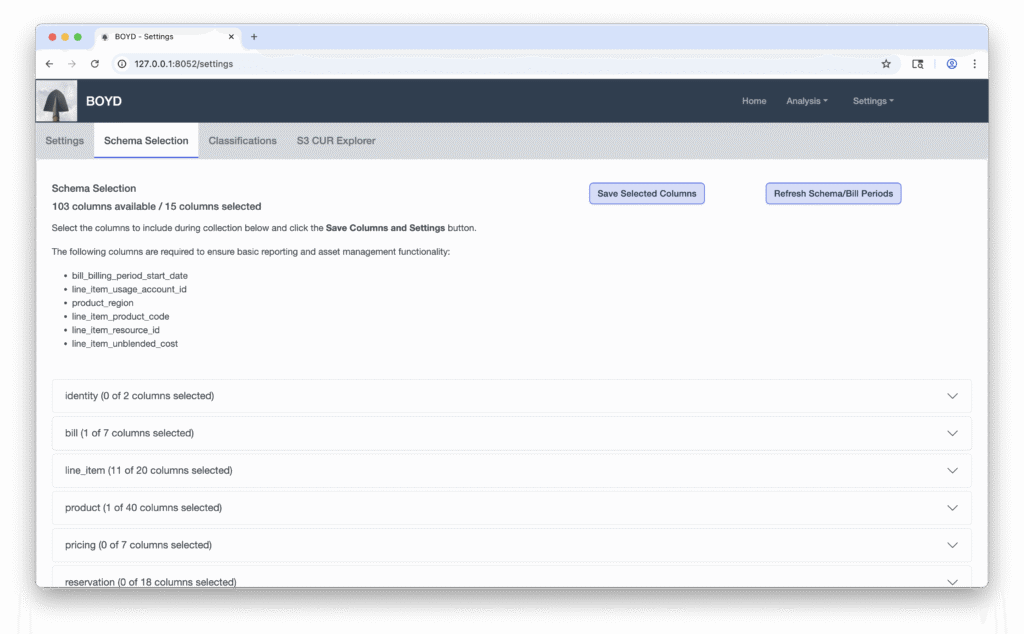
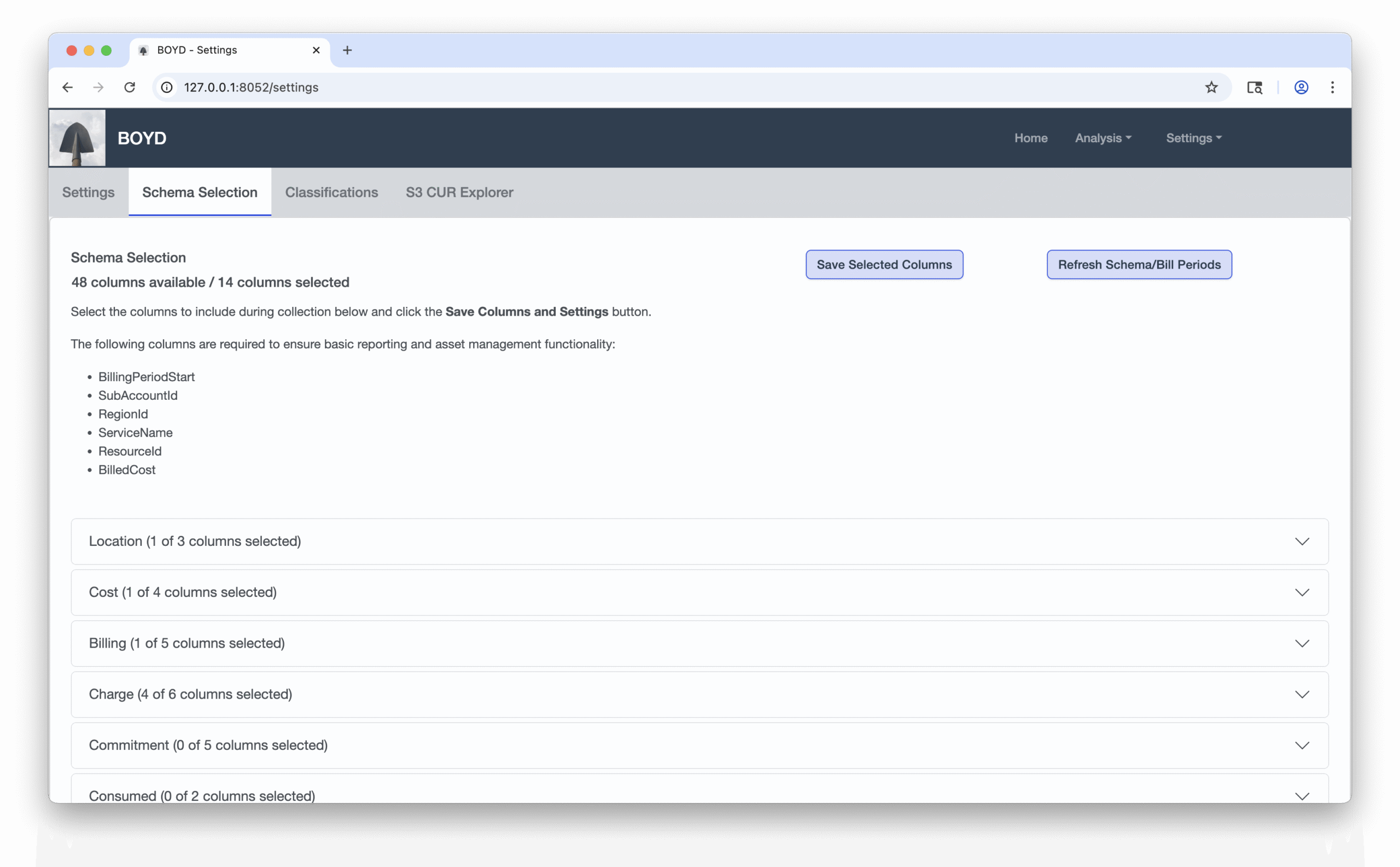
The BOYD required fields enable basic analysis of monthly results. Include line_item_usage_start_date or ChargePeriodStartDate if you want to analyze daily/hourly results. For CUR versions 1 and 2 most of the line_item_ fields can provide context around your types usage and consumption. Tag (resource_tags_user_) related fields can be useful for deriving organization applied context for resources.
S3 CUR Explorer
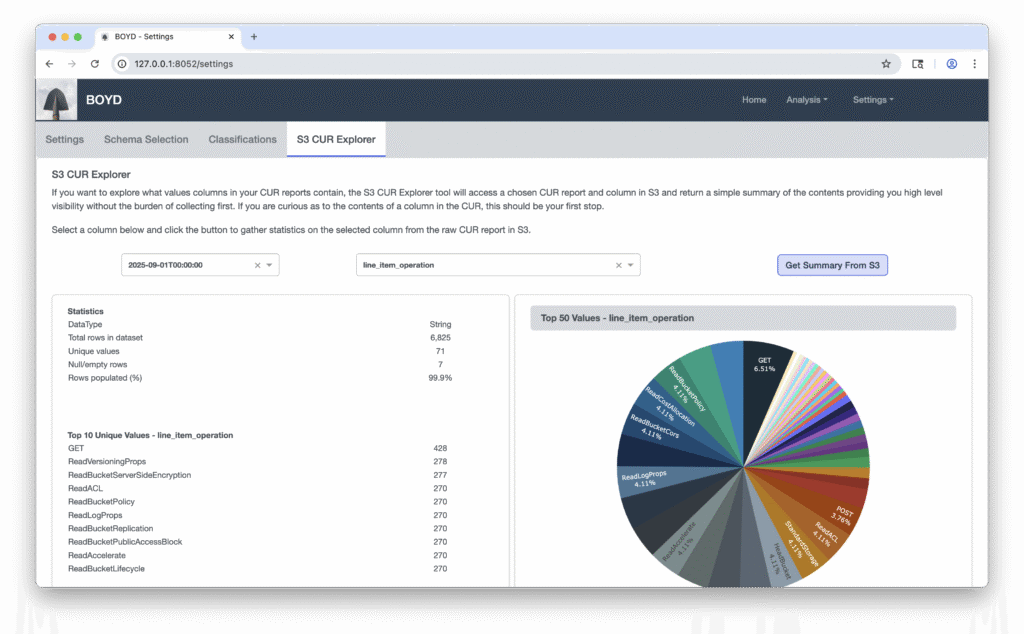
What about the other 90+ columns? The BOYD settings page includes a search utility called S3 CUR Explorer that provides a statistical summary of a CUR column’s contents using the raw data in S3. Select a bill period and column and you can quickly assess the top values in use and frequency.
Dig or Collect?
The best way to understand whether it is preferable to collect a column or use BOYD’s “Dig Mode” to retrieve context from AWS APIs is to explore a sample use case. If you are interested in analyzing RDS databases the CUR typically contains a number of useful columns that can help you analyze consumption, database engines and versions in use and more. Collecting these columns will provide historical context on when a value changed, but also introduce a lot of empty or null values in your data for non-RDS resources. Using “Dig Mode”, BOYD will retrieve and store the current configuration details returned by the RDS service’s API, which is a lot more context and detail than the CUR provides.
The main distinction is: are you auditing current configuration or desiring a view into historical changes. If you want to understand when RDS database engine versions changed, then include the column during collection. If you are trying to audit current resource settings then dig.
Don’t stress over column selection, but instead feel free to experiment. Because of the unpredictable nature of some CUR fields, BOYD is built to be very forgiving. For example, if you have collected data for several months then add a new selected column for collection (such as when you add a new cost allocation tag) if you include the column in filters or group by values, the value for data where the column did not exist will be “column not available”. This also means you can use BOYD to collect a column for one bill period, analyze results and disable the column from future collections when no longer required.
Filtering + Group By = Parquet Power
BOYD requires CUR data to be stored as parquet files and stores collected data as parquet, which use a columnar storage format. When reading from a CSV file, you must scan the entire file even if you only need a few columns. Parquet’s columnar layout allows direct access to specific columns without reading the entire dataset, making it far more performant when you only need a subset of the available columns.
When using BOYD, the fewer group by columns selected the quicker the results will be returned. Conversely, the more filters you utilize, the faster results will return. Performing a group by on resource IDs for example is about the worst thing you can do with CUR data for performance, but is also necessary to isolate unique resource context for “Dig Mode” excavations. It is highly recommended to apply account ID, product code and/or region filters when analyzing results using many group by columns or when working with large data sets. BOYD’s Column Details tab provides a similar view to your collected data as the S3 CUR Explorer discussed earlier to provide statistical context of your collected data.
Give BOYD a try today!